Introduction
This week, we began working with abdominal CR (Computed Radiography) images to classify gastrointestinal conditions such as small bowel obstruction, large bowel obstruction, and ileus. While this may initially resemble a conventional image classification task, the problem quickly reveals a deeper level of complexity.
Unlike natural images, abdominal radiographs are inherently difficult to interpret. Even experienced clinicians rely on subtle visual cues and global patterns rather than obvious localized features. Structures overlap significantly, soft tissue contrast is limited, and diagnostically relevant signals—such as gas distribution—are often faint and diffuse. More importantly, identifying an obstruction is not simply a matter of detecting a single abnormal region. Instead, it requires understanding how patterns are distributed across the entire abdominal cavity. This makes the task fundamentally different from typical object recognition problems.
This observation leads to a key question: which type of deep learning architecture can effectively capture both fine-grained local features and long-range global dependencies?
The CNN vs. Transformer Dilemma
Deep learning has significantly transformed medical image analysis, enabling automated detection of diseases across various imaging modalities. However, different model families come with inherent trade-offs.
Convolutional Neural Networks (CNNs) like ResNet, DenseNet, and EfficientNet have long dominated computer vision. Their success stems from their ability to learn hierarchical feature representations efficiently. They excel at detecting edges, textures, and localized structures, making them suitable for many medical imaging tasks. However, a key limitation of CNNs is their locality bias. Since convolutions operate on local neighborhoods, capturing global relationships requires stacking many layers, which is not always sufficient. In the context of abdominal imaging, this becomes problematic; for example, obstruction is often inferred from the overall distribution of gas rather than a single localized feature, and ileus may present as a pattern spanning multiple abdominal regions.
Vision Transformers (ViTs) address the limitations of CNNs by introducing self-attention mechanisms that allow every part of the image to interact with every other part. This provides strong global context modeling. However, Transformers typically have quadratic computational complexity with respect to image size, require large amounts of training data, and can be sensitive to noise and perturbations. Therefore, while ViTs are powerful, they are not always ideal when used in isolation—especially in medical imaging settings where data is limited.
MedViT: A Hybrid Architecture
To address these challenges, MedViT (Medical Vision Transformer) introduces a hybrid architecture that combines the strengths of CNNs and Transformers. The goal is to preserve local feature extraction capabilities while enabling efficient global context modeling. This design is particularly well-suited for abdominal obstruction detection, where diagnostic patterns emerge from both localized structures and their global arrangement.
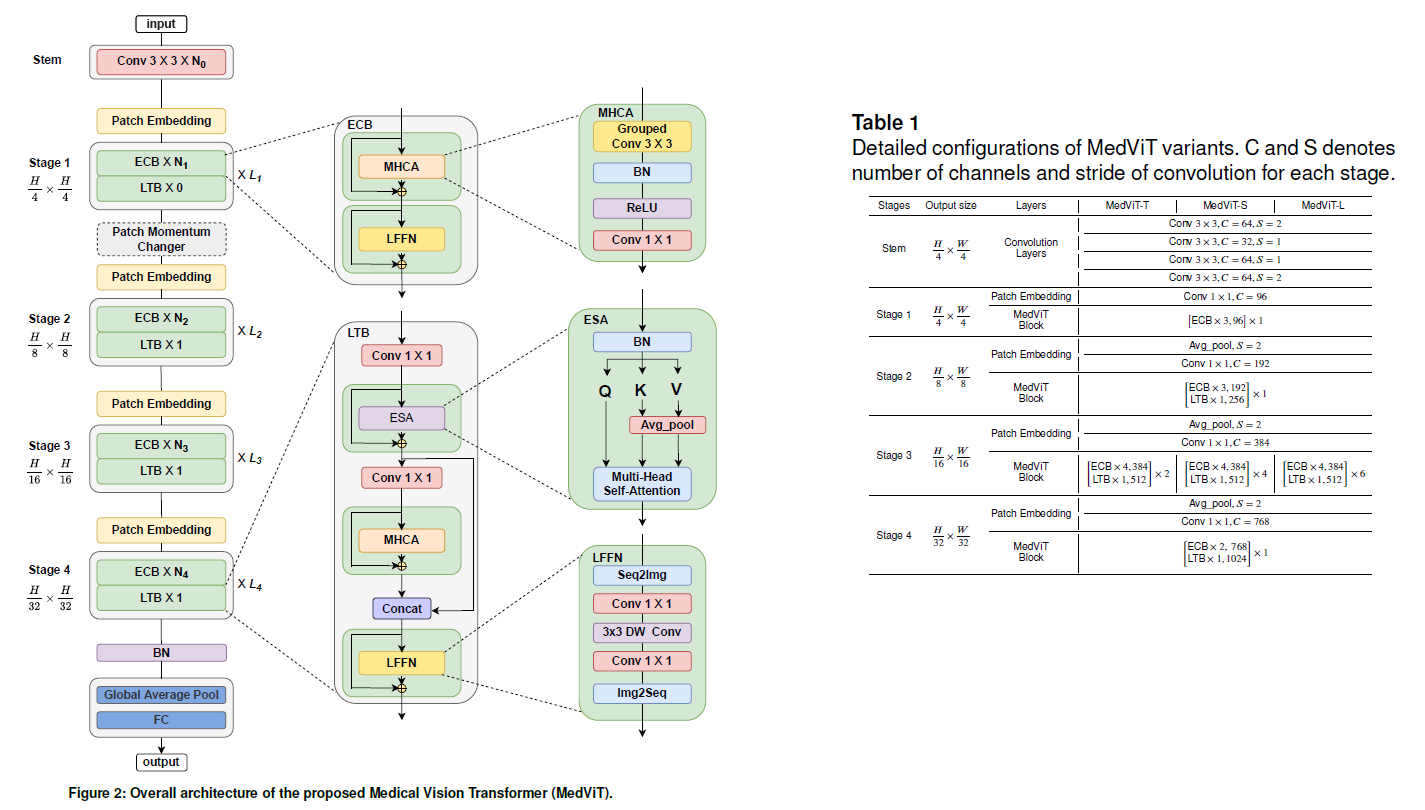
As illustrated above, the architecture alternates between convolutional and transformer-inspired blocks, enabling a balanced representation of spatial and contextual information. MedViT bridges the gap by combining:
- CNN-based local feature extraction
- Transformer-based global attention
- Efficient attention mechanisms to reduce computation
- Robust training strategies tailored for medical data
Key Components
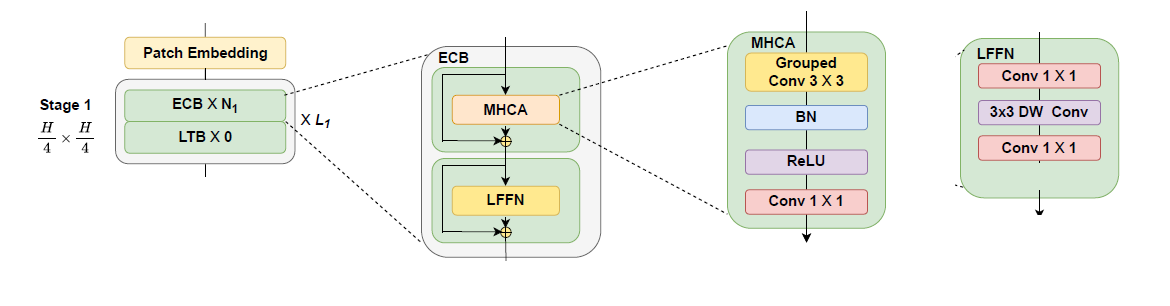
Efficient Convolution Block (ECB): Focuses on extracting local spatial features while maintaining computational efficiency. It incorporates Multi-Head Convolutional Attention (MHCA) and a Local Feed-Forward Network (LFFN). ECB preserves the inductive bias of CNNs while enhancing feature representation, resulting in improved robustness and reduced computational cost.
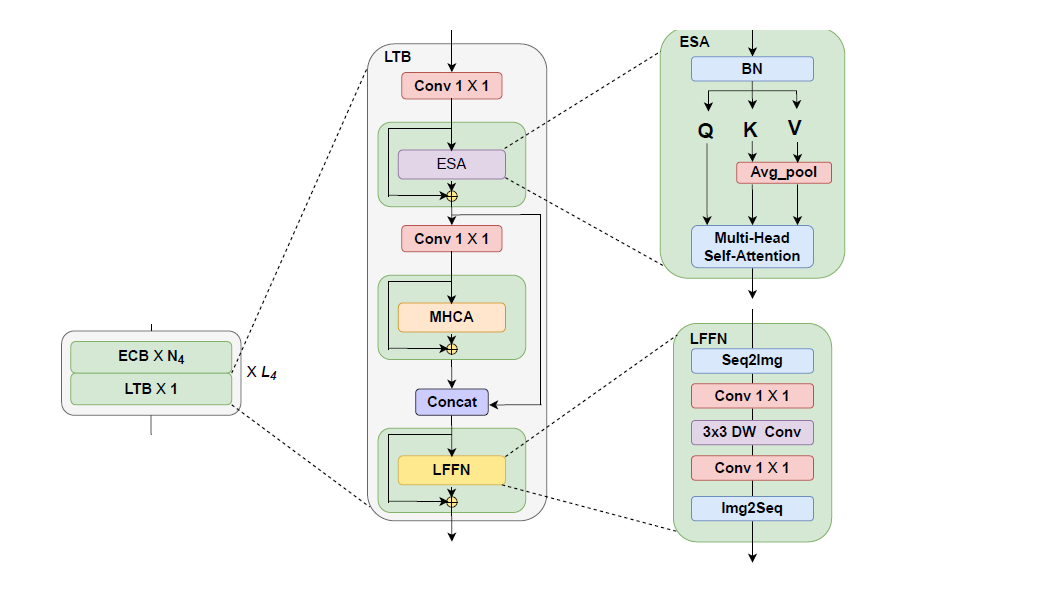
Local Transformer Block (LTB): Responsible for modeling global dependencies. It employs Efficient Self-Attention (ESA) along with feature fusion mechanisms and feed-forward layers. This allows the model to reason about global patterns across the entire image while maintaining efficiency.
Patch Momentum Changer (PMC): A feature-level augmentation technique designed to improve generalization by combining feature representations from different samples. This approach encourages the model to rely less on specific local cues and more on global patterns.
Performance and Interpretability
The quantitative results demonstrate that MedViT achieves the best overall balance across accuracy, precision, and F1-score. While some models such as ResNext50 obtain lower validation loss or higher recall, they fail to maintain consistent performance across all evaluation metrics. In contrast, MedViT provides a more stable and reliable performance, which is particularly important in medical decision-making scenarios.
| Model | Val Loss | Val Acc | Precision | Recall | F1 |
|---|---|---|---|---|---|
| MedViT | 0.4358 | 0.9183 | 0.9462 | 0.8936 | 0.9029 |
| UNet | 0.4471 | 0.9135 | 0.8397 | 0.7929 | 0.8016 |
| ResNext50 | 0.3910 | 0.9038 | 0.9026 | 0.9058 | 0.8883 |
| EfficientNetB0 | 0.4171 | 0.8894 | 0.8833 | 0.8705 | 0.8605 |
| ResNet18 | 0.4531 | 0.8798 | 0.8654 | 0.8788 | 0.8508 |
| UMamba | 0.4856 | 0.8798 | 0.8705 | 0.8282 | 0.8326 |
| SwinUMamba | 0.4958 | 0.8750 | 0.8429 | 0.8595 | 0.8421 |
| ResUNet++ | 0.5147 | 0.8622 | 0.8782 | 0.8372 | 0.8363 |
Model performance comparison.
Beyond numerical evaluation, it is also critical to understand how the model makes its predictions. For this purpose, we employ Grad-CAM (Gradient-weighted Class Activation Mapping) to visualize the regions that contribute most to the model's decision.
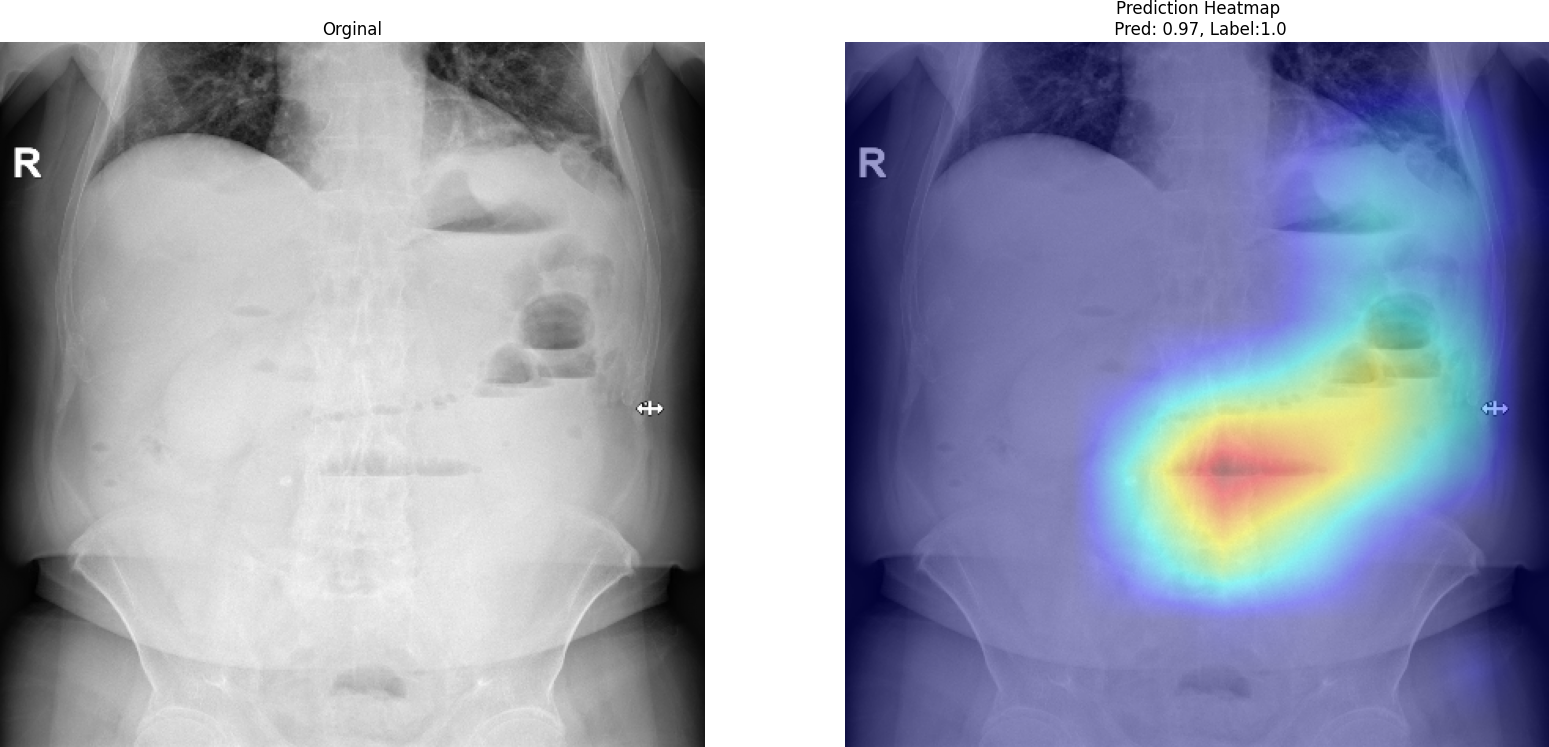
As shown in the Grad-CAM visualization, the model focuses on meaningful anatomical regions rather than irrelevant background areas. The highlighted regions correspond to gas distribution patterns and abdominal structures that are clinically associated with obstruction. This behavior suggests that MedViT does not rely on spurious correlations but instead learns medically relevant features. Such interpretability is essential for building trust in AI-assisted diagnosis, especially in high-stakes clinical environments.
Conclusion
MedViT demonstrates that hybrid architectures can outperform both pure CNN and pure Transformer models in medical imaging tasks. By combining local feature extraction with global reasoning, it provides a more comprehensive understanding of complex visual patterns. In the context of abdominal obstruction detection, such a design is not merely advantageous—it is essential for achieving reliable and clinically meaningful results.