Introduction
As an HPC/AI expert at VISTA Lab, one of my responsibilities is future-proofing the computing infrastructure that researchers depend on. When you are making decisions about a cluster (the memory hierarchy, storage architecture, interconnects), you are not just buying hardware for today's workloads. You are making a bet on where the field is heading.
So when a paper comes out that could shift the balance between GPU memory and host memory in LLM inference, it is worth paying attention to. That paper is Engram, published by DeepSeek in January 2026. It introduces a new architectural component for LLMs built around a straightforward observation: language models currently use the same computational pathway for two very different tasks.
When a language model answers a factual question, say the boiling point of water or the name of a country's capital, it does not look that fact up. It recomputes it, from scratch, through the same deep reasoning machinery it would use to solve a complex logical problem. Every forward pass mixes static knowledge retrieval with dynamic reasoning, with no architectural distinction between the two.
Engram proposes separating these by giving the model a dedicated memory module for static knowledge, structurally distinct from the reasoning pathway.
How Engram Works
Every time a language model generates a token, it is doing two things at once. Some of it is pure recall: recognizing that "Alexander the Great" is a historical figure, or that "Milky Way" is a galaxy. The rest is genuine reasoning: understanding context, following logic, building an answer that did not exist before. Current Transformer architectures make no distinction between the two. Recall and reasoning pass through the same attention and feed-forward layers, every time, for every token.
Engram adds a dedicated memory module to the network to separate these two tasks. The idea is simple. The module looks at short sequences of consecutive tokens (N-grams), hashes them, and retrieves a pre-stored learnable embedding from a large lookup table. No attention, no search, just a direct table hit. If the N-gram is in the table, the embedding comes back instantly. If it is not, the model falls back to its normal behavior. Because lookups are so cheap, the table itself can be enormous without adding meaningful compute cost.
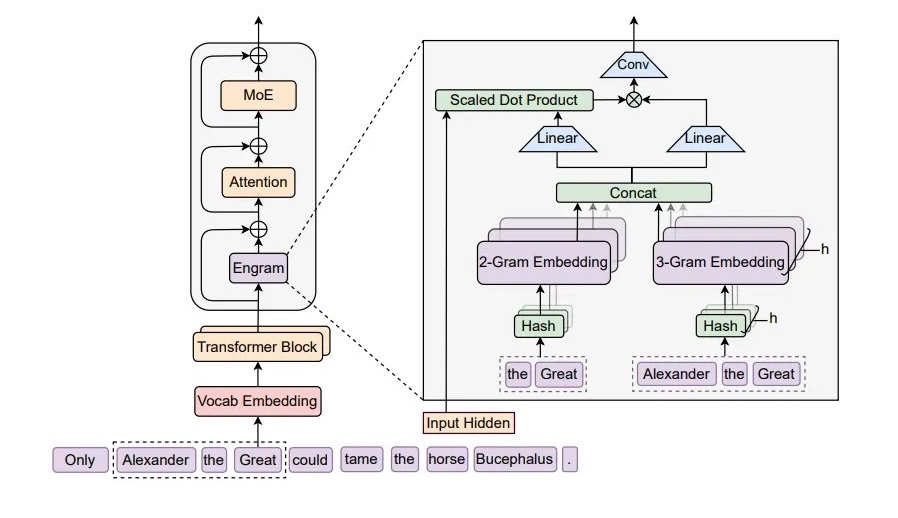
Of course, not every token benefits from memory retrieval. A proper noun like "Diana, Princess of Wales" is a static pattern that the model should just know. A word like "analyzes" in the middle of a sentence requires understanding context, not recall. So the module includes a learned gate that controls how much of the retrieved memory actually gets used at each position.
When the token is part of a known pattern, the gate opens and the memory gets fused into the hidden state. When the token needs reasoning, the gate stays mostly closed and the Transformer handles it on its own. You can see this in Figure 2: proper nouns and fixed phrases light up in dark red, while ordinary tokens that depend on context stay light.
One thing to be clear about: Engram does not make individual tokens cheaper to compute. Every token still passes through the full depth of the network. There is no layer skipping or early exit. What changes is what the computation gets spent on. In a standard Transformer, the feed-forward layers do double duty. They store static factual knowledge in their weights and they perform the transformations needed for reasoning.
With Engram, that assembly is handled by the memory module before the backbone even starts. The feed-forward weights that were previously tied up storing and reconstructing these patterns are now free to focus on reasoning. The paper's analysis shows that layer 5 of an Engram model produces representations roughly equivalent to layer 12 of a standard MoE model. The network is not any deeper, but it gets more done per layer.
The Memory Hierarchy Engram Requires
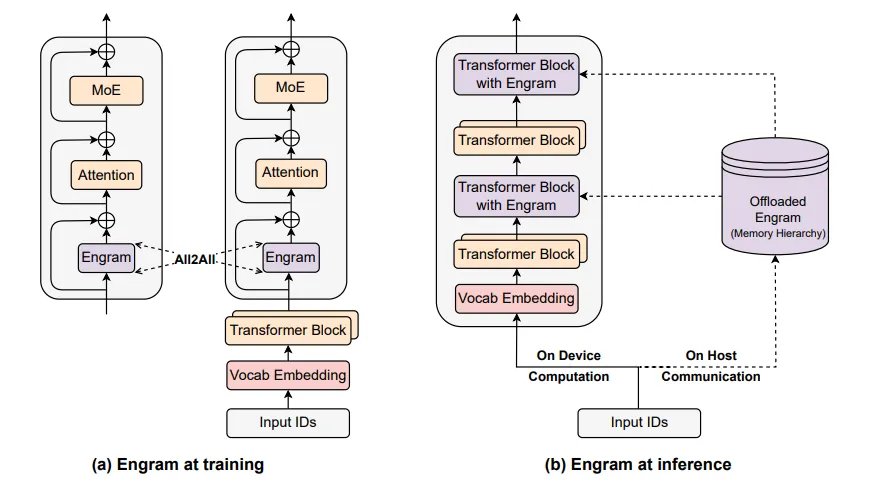
What makes Engram practically interesting from an infrastructure standpoint is that it does not just change how a model thinks. It changes where a model's parameters physically live.

The reason this works is that Engram's memory lookups are deterministic. The system knows exactly which N-gram embeddings it needs before the forward pass starts, because the lookup keys come directly from the input tokens through hashing. There is nothing to wait for, no attention scores to compute first, no dynamic routing decision.
That means the host can prefetch embeddings asynchronously: while the GPU is still busy with the current layer's computation, the next batch of memory lookups is already in flight over PCIe. The GPU never stalls waiting for data. The paper demonstrates this with a 100 billion parameter table offloaded entirely to host DRAM, showing less than 3% overhead on throughput.
To get a sense of the physical scale involved: that 100B table stored in half-precision (BF16/FP16) occupies roughly 200 GB of system RAM per node. The production-scale Engram-27B model uses a more modest 5.7 billion parameter table (approximately 11 GB), and Engram-40B uses 18.5 billion parameters (approximately 37 GB).
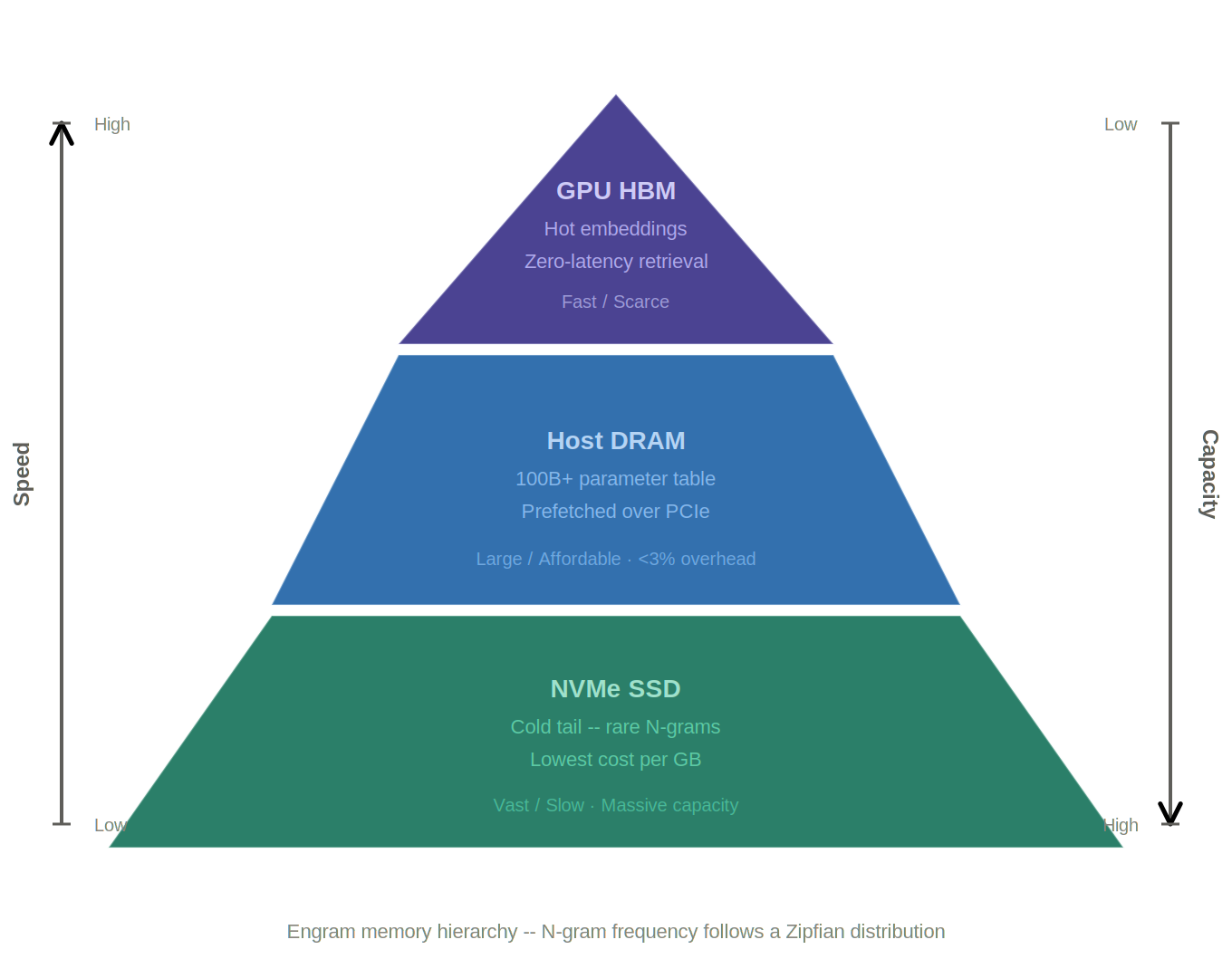
The paper also proposes a multi-level cache hierarchy on top of this, based on a simple observation: natural language N-grams follow a Zipfian distribution. A small number of patterns (common phrases, frequent named entities) account for the vast majority of lookups. The long tail of rare patterns is accessed far less often. This maps naturally onto a tiered memory design.
Today, when you size a cluster for LLM inference, the question is mostly about GPU count and HBM capacity. If Engram's approach holds up, CPU RAM and NVMe become first-class participants in the memory system of the model itself, not just overflow or swap space.
Conclusion
If the separation of static memory from dynamic computation holds up at production scale, the memory tables will only grow. The paper already demonstrates a clean power-law relationship between table size and model quality: more memory slots, better performance, at near-zero additional compute cost. A 100-billion-parameter table is the proof of concept. A trillion is not out of the question.
For inference clusters, this changes how you think about node specifications. Host DRAM capacity and NVMe storage become direct contributors to model quality, not just system overhead. Cluster procurement decisions that currently revolve almost exclusively around GPU count and HBM size will need to weigh system memory density and storage tier latency just as carefully.
Training tells an even more demanding story. During training, the embedding tables cannot be offloaded to host memory the way they can at inference time. They live on GPU HBM, sharded across devices via All-to-All communication, and they need to be there for both the forward pass and gradient updates. As these tables scale from tens of billions to hundreds of billions of parameters, GPU memory pressure during training will increase significantly, even if inference stays cheap.
The direction Engram points in is worth watching. If static knowledge can be cleanly separated from reasoning and stored cheaply outside of HBM, the economics of running large models change in ways that favor memory-rich nodes over GPU-heavy ones.
🚀 Free GPU Resources for Researchers
If you are a researcher, SME, or startup in Türkiye working on AI and HPC workloads, TÜBİTAK ULAKBİM offers programs that provide free GPU computing resources through the TRUBA infrastructure. Additionally, Türkiye is a consortium member of Mare Nostrum 5, one of the EuroHPC Joint Undertaking's pre-exascale supercomputers hosted at the Barcelona Supercomputing Centre.
National Access Applications for MareNostrum 5 are currently open. Check them out:
References
- X. Cheng, W. Zeng, D. Dai, et al. Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models, 2026. View on arXiv