In the high-stakes theater of modern warfare, the strategic integration of Reinforcement Learning (RL) into military aviation marks a transition from "automated" flight to truly "autonomous" combat. While traditional fly-by-wire systems follow predefined laws of physics and logic, RL allows a system to learn the optimal policy for mapping a state to an action by maximizing a cumulative reward signal.
Reinforcement Learning: Foundational Concepts
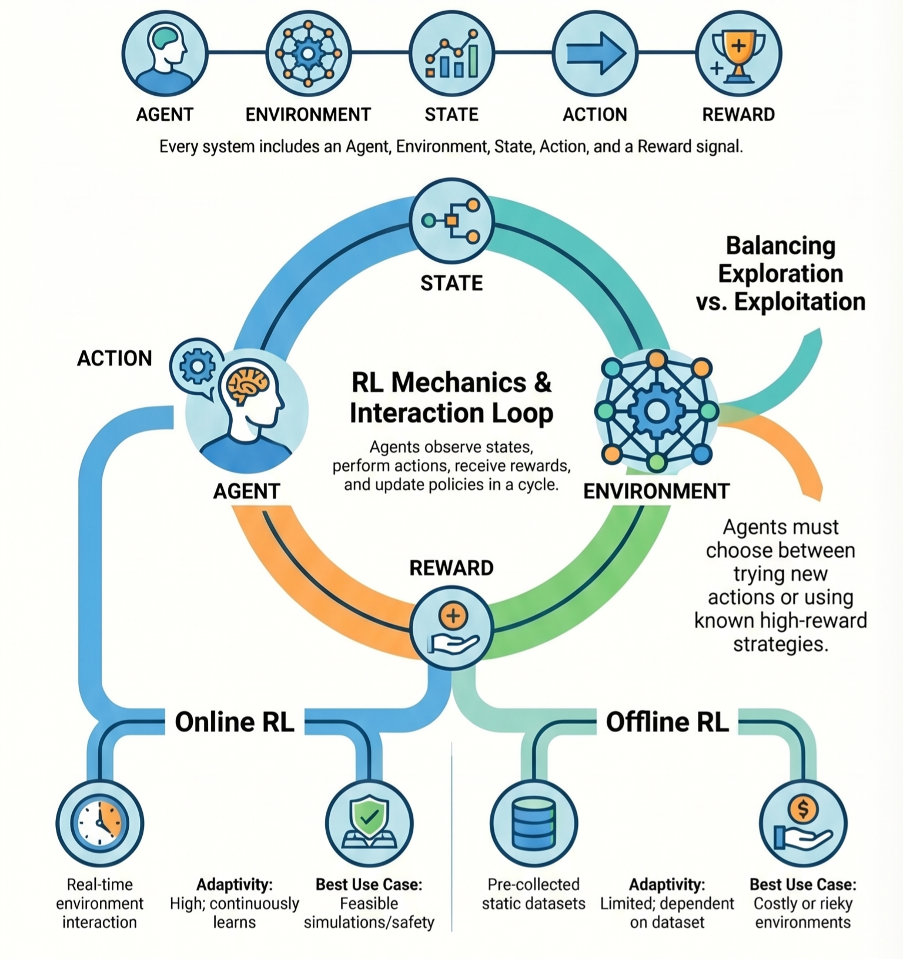
Instead of relying on labeled datasets like supervised learning, RL uses feedback in the form of rewards—simple signals that indicate how good or bad an outcome is. Over time, the agent learns a strategy, called a policy (π), that tells it what action to take in each situation to achieve the best long-term results. At the core of RL is a mathematical framework known as a Markov Decision Process (MDP).
An MDP is defined by five key components:
- States (S): All possible situations the agent can encounter.
- Actions (A): The set of choices available to the agent.
- Transition function (P): How the environment changes in response to actions.
- Reward function (R): The feedback signal that evaluates actions.
- Discount factor (γ): A value between 0 and 1 determining how much the agent values future rewards compared to immediate ones.
In each step, the agent observes its current state, takes an action based on its policy, moves to a new state, and receives a reward, with the ultimate goal of maximizing the cumulative reward over time.
Key Algorithms and Taxonomy
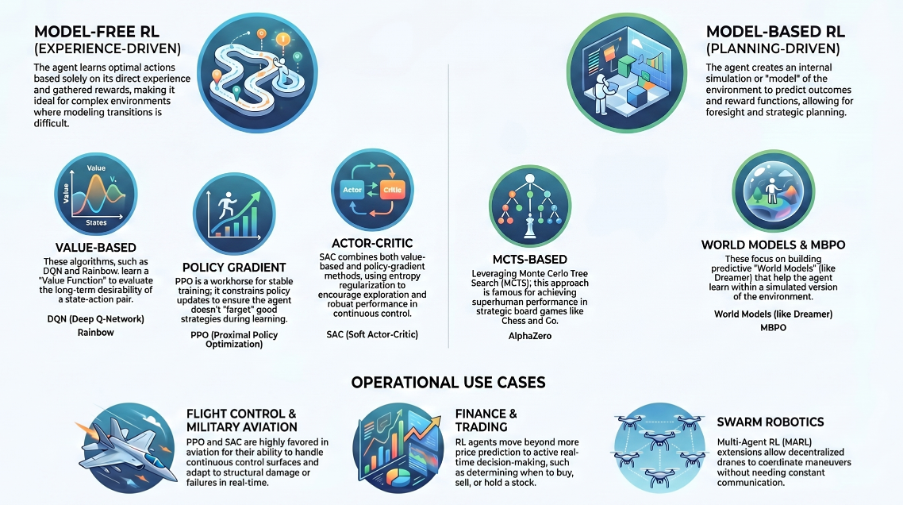
The RL ecosystem categorizes algorithmic families into experience-driven Model-Free methods and planning-driven Model-Based models. Model-Free RL highlights algorithms that learn purely from experience without trying to predict the environment's physics, including Value-Based (DQN), Policy Gradient (PPO), and Actor-Critic (SAC) methods. Conversely, Model-Based RL focuses on building an internal simulation of the world, utilizing MCTS-Based systems (like AlphaZero) and World Models (like Dreamer) for strategic foresight. In aviation, PPO and SAC are industry favorites for their stability in handling continuous flight control surfaces.
The Strategic Fit for Military Aviation
RL offers three critical strategic advantages in modern air combat:
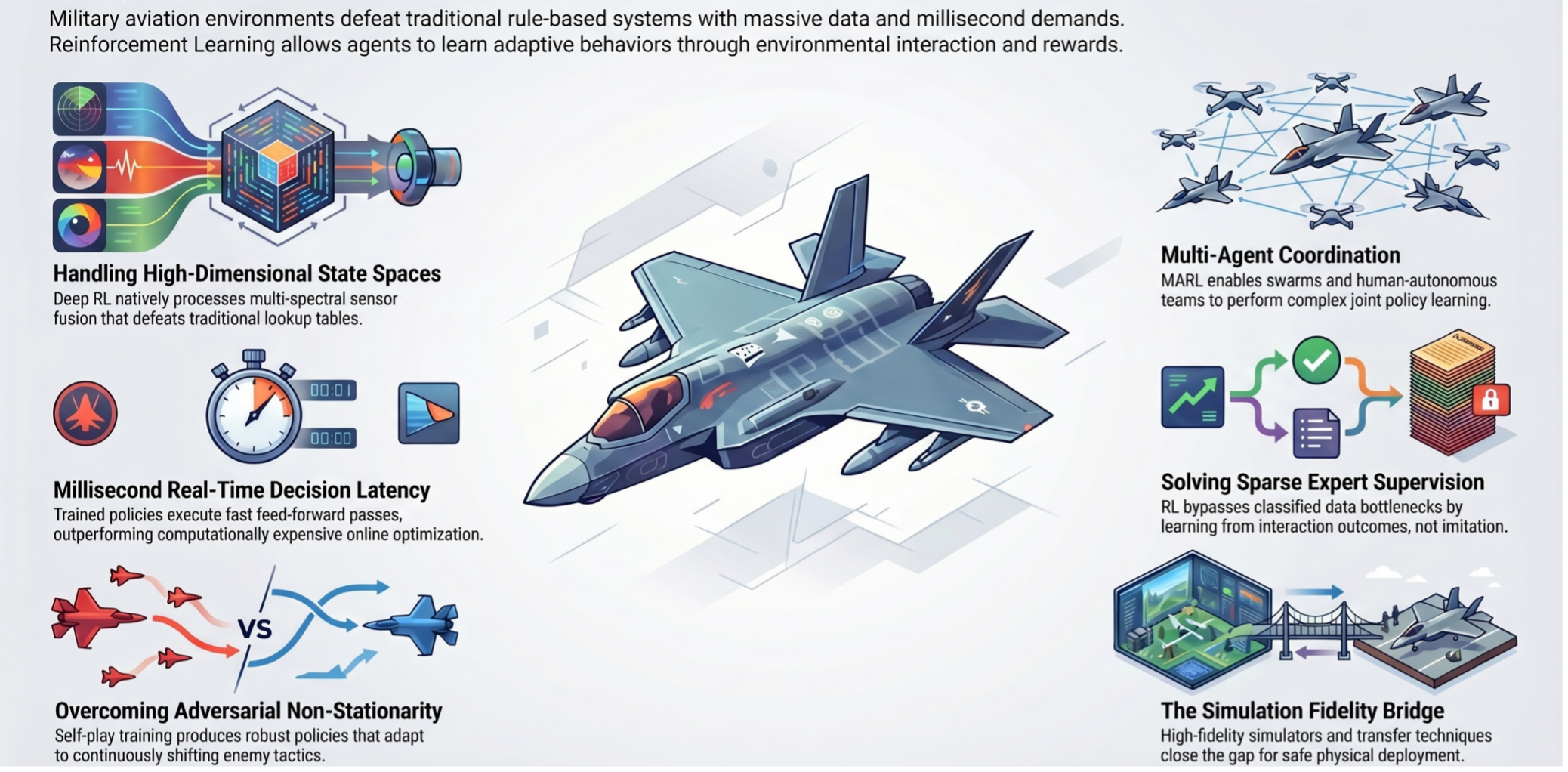
- Envelope Expansion: Traditional flight controllers are limited by safety envelopes designed for humans. RL-driven autonomous systems can safely explore the extreme edges of the flight envelope.
- OODA Loop Optimization: The military OODA loop (Observe, Orient, Decide, Act) is the heartbeat of combat. In contested environments with hypersonic missiles and electronic warfare, RL shrinks the window to "Decide" down to milliseconds.
- Training and Scaling: The immense cost and time required to train a human fighter pilot can be mitigated by RL, which allows for the rapid "cloning" of elite tactical intelligence across an entire fleet of Unmanned Combat Aerial Vehicles (UCAVs).
Active Application Domains
Autonomous Air Combat Manoeuvring
In 2020, DARPA's AlphaDogfight Trials demonstrated a watershed moment: an RL-trained agent developed by Heron Systems consistently defeated an experienced human F-16 pilot across five simulated within visual range engagements. The agent used a PPO-based architecture trained entirely in simulation. Building on this, Multi-Agent RL (MARL) extensions like QMIX and MAPPO now enable wingman assets to coordinate maneuvers and allocate threats without real-time inter-agent communication latency.
Autonomous Flight Control and Swarm Coordination
Traditional flight control laws use linear time-invariant (LTI) models valid only near specific operating points, whereas RL controllers operate across the full non-linear envelope. NASA and AFRL have invested in SAC-based adaptive controllers that maintain controlled flight even with up to a 40% reduction in control authority due to structural damage. Furthermore, for low-cost attritable UAS platforms, MARL-based policies exhibit emergent swarm behaviors—such as encirclement and distributed surveillance—making the swarm resilient to communication degradation.
Intelligent Electronic Warfare and Mission Planning
Electronic warfare is a quintessential adversarial RL problem where both the jamming platform and target receiver continuously adapt. DQN-based agents trained against diverse emitters can learn frequency-hopping and beam-steering strategies, outperforming conventional rule-based systems by up to 30% in contested spectrum conditions. Operationally, hierarchical RL architectures are being applied to NP-hard problems like route optimization and time-on-target scheduling for multi-platform strike packages.
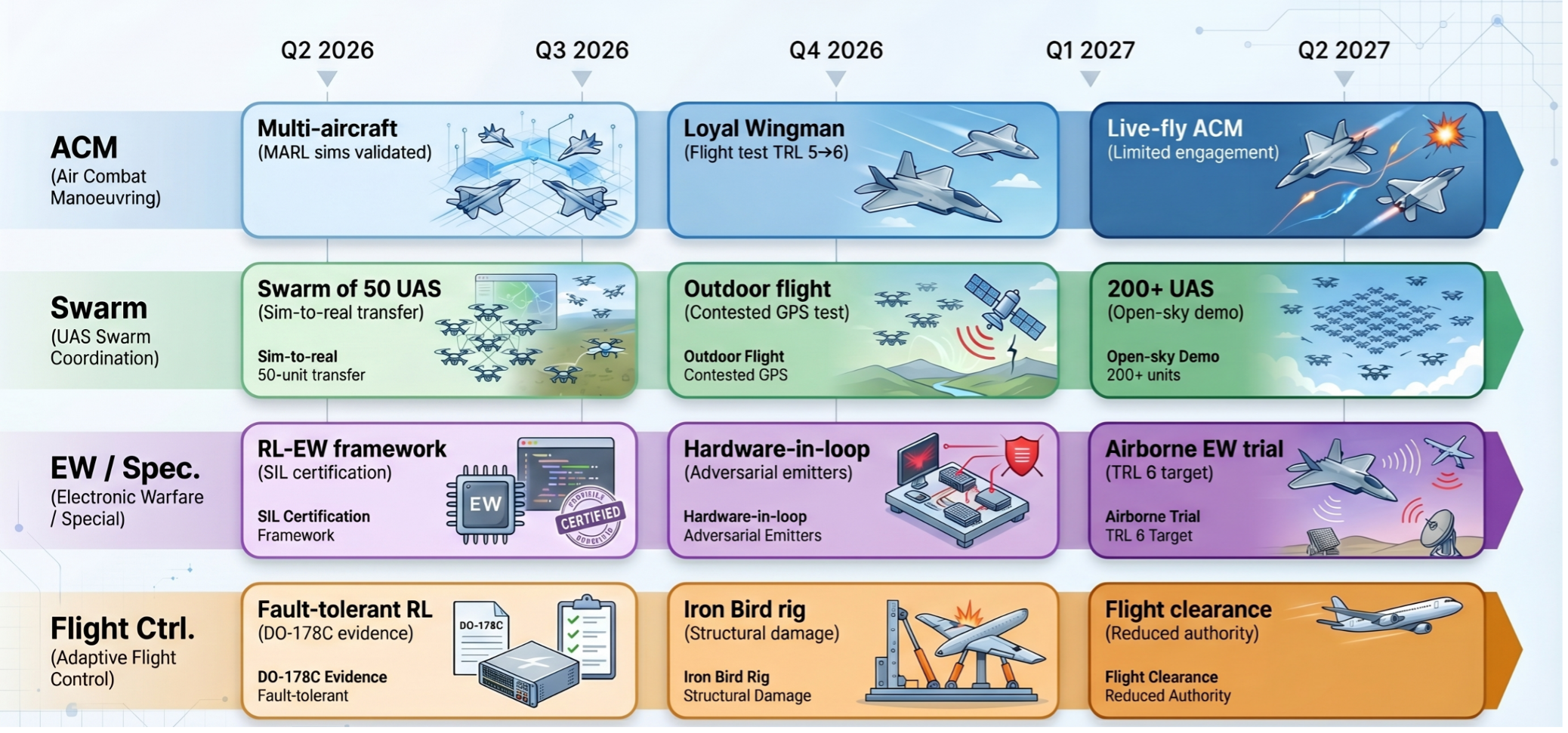
Vision 2027: The Technology Roadmap
Looking ahead to mid-2027, the field stands at an inflection point, transitioning from proof-of-concept demonstrations in simulation to constrained real-world validation.
Conclusion
Reinforcement Learning has moved from a theoretical curiosity to a tangible force. RL-driven systems demonstrate an ability to operate effectively where deterministic, rule-based approaches break down—specifically in environments characterized by high dimensionality, adversarial non-stationarity, and the absence of reliable expert supervision.
Yet the field's most consequential challenges remain unresolved. The reward misspecification problem—translating complex operational intent into a safe mathematical signal—is arguably the central unsolved problem in applied RL. Adversarial robustness is a persistent concern, alongside the sim-to-real gap. Above all, the legal and ethical architecture governing the use of autonomous systems in lethal operations remains underdeveloped. Questions of accountability, proportionality, and compliance with international humanitarian law require deliberate governance effort. Closing the gap between what these systems can do in simulation and what they can be trusted to do in the field will require robust certification frameworks, interpretability tools, and international norms.
References
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction (2nd ed.). MIT Press.
- Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
- Haarnoja, T., Zhou, A., Abbeel, P., & Levine, S. (2018). Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. Proceedings of ICML.
- DARPA (2020). AlphaDogfight Trials Final Event Results. Defense Advanced Research Projects Agency.
- Tobin, J., Fong, R., Ray, A., Schneider, J., Zaremba, W., & Abbeel, P. (2017). Domain randomization for transferring deep neural networks from simulation to the real world. IEEE/RSJ IROS.
- Rashid, T., Samvelyan, M., de Witt, C. S., Farquhar, G., Foerster, J., & Whiteson, S. (2018). QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning. Proceedings of ICML.
- EASA (2023). Artificial Intelligence Roadmap 2.0: Human-Centric Approach to AI in Aviation. European Union Aviation Safety Agency.
- Achiam, J., Held, D., Tamar, A., & Abbeel, P. (2017). Constrained policy optimization. Proceedings of ICML.
- Chen, L., Lu, K., Rajeswaran, A., Lee, K., Grover, A., Laskin, M., … & Mordatch, I. (2021). Decision transformer: Reinforcement learning via sequence modeling. NeurIPS.
- National Security Commission on Artificial Intelligence (2021). Final Report. NSCAI, Washington D.C.