Today, the rapid development of artificial intelligence (AI) algorithms, especially Deep Neural Networks (DNN) and Large Language Models (LLM), puts immense pressure on computing infrastructures. Current AI architectures mostly rely on massive data centers, high-performance graphics processing units (GPUs), and unlimited energy resources with cloud systems. While cloud services have high computational power, transferring data from the cloud is not always a viable option for every task since time-sensitive operations require a very short response time.
Edge computing is one of the fundamental solutions for time-sensitive operations. In edge computing, instead of transferring all of the data to the cloud or doing high computational tasks on end devices which have little power, there is a device that is used at the network edge which can handle computing tasks on both data sent to and received from the cloud as shown in Figure 1. [1]
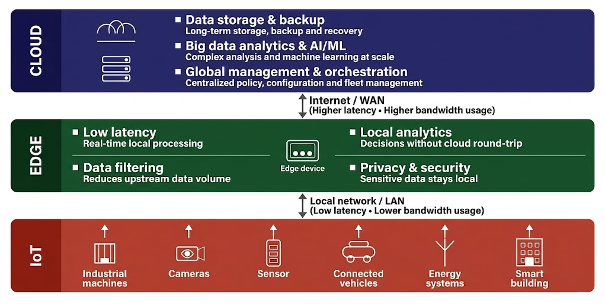
One of the main issues with edge computing is the limitation of power in all areas. Unlike cloud systems, edge computing hardware doesn’t have the luxury of a robust operating environment. Unlimited electrical power, massive memory capacities, or active cooling systems are not available in edge devices; they must perform their duties under strict constraints in a physical world where timing, reliability, and efficiency outweigh massive operation counts [3].
In this context, although traditional Artificial Neural Networks (ANN) offer high accuracy rates and mature software tools, they are quite far away from being a sustainable solution for edge devices due to their high computational density, matrix multiplication-based architectures, and constant power consumption profiles [4].
A promising framework for edge AI is the Spiking Neural Network (SNN) which is inspired by the biological neurons. Unlike conventional ANNs which process data in a continuous fashion, SNNs communicate with discrete spikes in a similar way to a biosignal crossing transmission threshold. In a traditional deep learning model, every layer does computing for every input, every time. When the sources are limited, as we have in the network edge, this is expensive. By contrast, the SNNs only performs calculations when a spike arrives. This event-driven structure is a good fit for cases that have limited sources like edge devices. This blog post explores why SNN technology is a good fit for edge computing by analyzing its biological foundations, encoding strategies and training algorithms.
Biological Foundations and Mathematical Dynamics of Spiking Neural Networks (SNN)
Traditional artificial neural networks treat the activation levels of neurons as continuous values. In reality, the brain uses discrete and time-based electrical signals (spikes) to transmit and process information [5]. SNNs mimic this structure, ensuring that neurons in the network only activate and fire (firing action potential) when their internal membrane potential crosses a specific threshold value [5]. This fundamental biological architecture renders the system event-driven, thus causing computation across the network to become highly sparse and achieving incredible power savings relative to the continuous system.
Encoding Mechanisms
Real-world data that we acquire from the edge sensors (e.g., pixel intensities from cameras or audio frequencies from microphones) are continuous and analog. For SNNs to process this data, the analog information must first be converted into discrete spikes, meaning it must be "encoded". Industrial standards rely on different techniques such as rate coding, temporal coding, phase coding, direct coding, etc. The correct encoding strategy directly impacts the speed and energy efficiency of the SNN architecture [6,7,8,9].
SNN Training Paradigms and Algorithmic Challenges
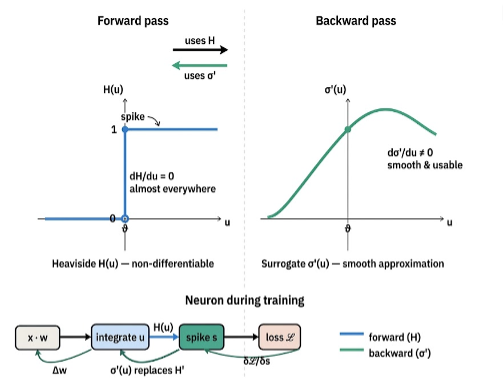
Traditional ANNs are trained via gradient descent methods, which calculate the derivative of activation functions and propagate the errors backward through the network. However, the neuron firing mechanism in SNNs is mathematically a step function. This binary behavior is non-differentiable and it causes gradients to vanish, making it impossible to optimize the network's weights using only traditional deep learning methods [6,7]. Although it’s considered the primary technical barrier for this technology, there are several solutions -few of which explained below- in the literature.
ANN-to-SNN Conversion
Rather than training the SNN model which is hard to optimize, an existing ANN can be converted into an SNN with the right steps. The conversion methods systematically set suitable firing thresholds for neurons across different network layers, ensuring that the integrate-and-fire (IF) spike rates closely match the corresponding analog ReLU activations. This allows us to fully leverage backpropagation-based training, which is well established for ANNs. [10]
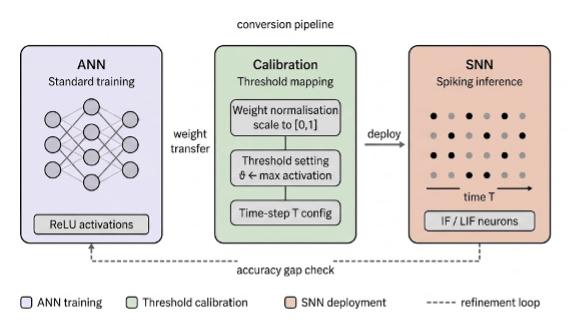
Direct Training with the Surrogate Gradient Approach
Since it’s not feasible to use backpropagation with non-differentiable inputs, the surrogate gradient approach takes an approximation of the signal in a way that is differentiable. This way it’s possible to use backpropagation and achieve better optimized parameters for the network. Though it seems like a perfect solution, the surrogate gradient method is an approximation in the end, and may mislead the gradient descent direction in multi-layer SNNs [9].
Conclusion
While conventional ANNs provide high accuracy and mature tooling, their continuous, computationally demanding nature makes them less suitable for deployment on edge devices with limited power, memory, and latency budgets. SNNs significantly reduce redundant computation, enabling improved energy efficiency for edge applications. However, despite their advantages, SNNs are not without challenges yet. The non-differentiable nature of spike generation complicates training, resulting in the need of alternative approaches such as ANN-to-SNN conversion and surrogate gradient methods. These methods come with other decisions to make to achieve a better optimization. With more research into more robust training algorithms, improved encoding techniques, and specialized neuromorphic hardware it’ll be possible to use SNNs with their full potential. As the need for real-time, distributed AI systems rise, SNNs are well-positioned to play a key role in the process.
References
- [1] W. Shi and S. Dustdar, "The Promise of Edge Computing," in Computer, vol. 49, no. 5, pp. 78-81, May 2016, doi: 10.1109/MC.2016.145.
- [2] Wazir Zada Khan, Ejaz Ahmed, Saqib Hakak, Ibrar Yaqoob, Arif Ahmed, Edge computing: A survey, Future Generation Computer Systems, Volume 97, 2019, Pages 219-235, ISSN 0167-739X, https://doi.org/10.1016/j.future.2019.02.050.
- [3] Vivienne Sze, Yu-Hsin Chen, Tien-Ju Yang, Joel Emer, Efficient Processing of Deep Neural Networks: A Tutorial and Survey, (2017) arXiv:1703.09039
- [4] Roy, K., Jaiswal, A. & Panda, P. Towards spike-based machine intelligence with neuromorphic computing. Nature 575, 607–617 (2019). https://doi.org/10.1038/s41586-019-1677-2
- [5] Maass, W. (1997). "Networks of spiking neurons: the third generation of neural network models." Neural networks, 10(9), 1659-1671.
- [6] E. O. Neftci, H. Mostafa and F. Zenke, "Surrogate Gradient Learning in Spiking Neural Networks: Bringing the Power of Gradient-Based Optimization to Spiking Neural Networks," in IEEE Signal Processing Magazine, vol. 36, no. 6, pp. 51-63, Nov. 2019, doi: 10.1109/MSP.2019.2931595.
- [7] Sengupta A, Ye Y, Wang R, Liu C and Roy K (2019) Going Deeper in Spiking Neural Networks: VGG and Residual Architectures. Front. Neurosci. 13:95. doi: 10.3389/fnins.2019.00095
- [8] Youngeun Kim, Hyoungseob Park, Abhishek Moitra, Abhiroop Bhattacharjee, Yeshwanth Venkatesha, Priyadarshini Panda (2022) Rate Coding or Direct Coding: Which One is Better for Accurate, Robust, and Energy-efficient Spiking Neural Networks? arXiv:2202.03133 https://doi.org/10.48550/arXiv.2202.03133
- [9] Zihan Huang, Wei Fang, Tong Bu, Peng Xue, Zecheng Hao, Wenxuan Liu, Yuanhong Tang, Zhaofei Yu, Tiejun Huang (2025) Differential Coding for Training-Free ANN-to-SNN Conversion, Computer Vision and Pattern Recognition, arXiv:2503.00301
- [10] Bing Han, Gopalakrishnan Srinivasan, Kaushik Roy, (2020), Neural and Evolutionary Computing, RMP-SNN: Residual Membrane Potential Neuron for Enabling Deeper High-Accuracy and Low-Latency Spiking Neural Network, arXiv:2003.01811