For many years, Convolutional Neural Networks (CNNs) dominated FPGA-based acceleration research because of their regular computational structures and efficient data reuse characteristics. However, Transformer architectures are now gaining widespread attention thanks to their remarkable success in computer vision and natural language processing tasks [2].
Although Transformers achieve superior performance in many AI tasks, their reliance on global self-attention mechanisms introduces significant hardware implementation challenges. In particular, irregular memory access patterns and high bandwidth requirements make efficient FPGA deployment considerably more complex compared to CNN-based models.
Why FPGA for Neural Network Inference?
Unlike CPUs and GPUs, FPGAs allow developers to customize hardware datapaths according to the structure of a neural network model. This flexibility enables the implementation of highly parallel and deeply pipelined architectures optimized for neural network inference workloads [3].
The main advantages of FPGA-based inference acceleration include: [4]
- Massive parallelism
- Deterministic low latency latency
- Lower power consumption compared to CPUs and GPUs
- Flexible numerical precision support (e.g., INT8, FP16, and fixed-point arithmetic)
- Custom memory hierarchies
These properties make FPGAs especially suitable for edge AI applications where real-time processing and power efficiency are critical [5]. Typical FPGA deployment domains include:
- Autonomous vehicles
- Smart surveillance systems
- Medical imaging
- Industrial inspection
- Robotics
- Edge computing devices
CNN Architectures on FPGA
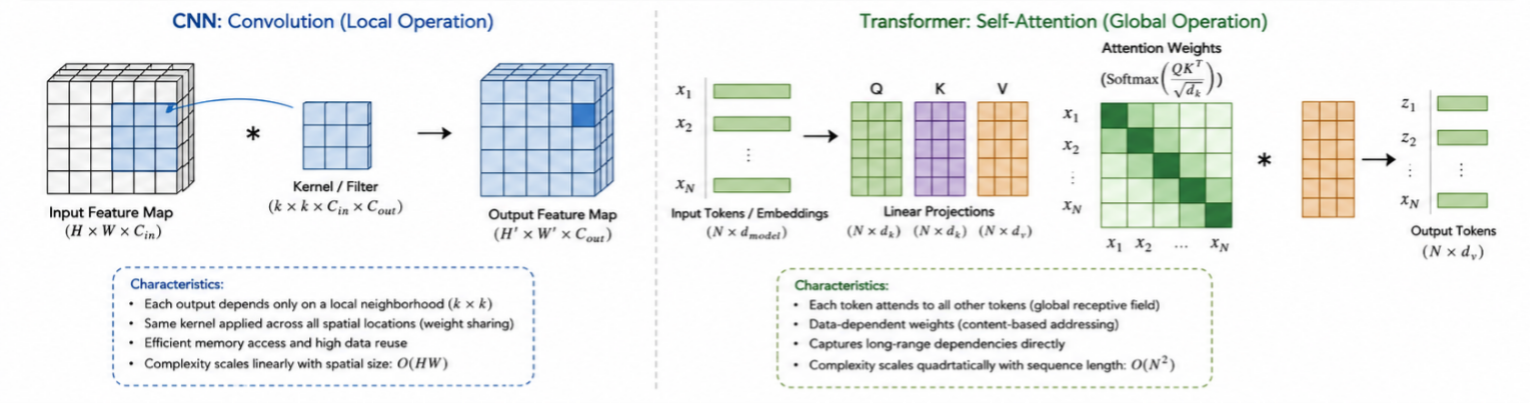
CNNs rely heavily on convolution operations that exhibit highly regular and repetitive computation patterns. This regularity maps efficiently onto FPGA fabrics and allows designers to exploit spatial parallelism and data reuse [6].
Because convolution kernels are repeatedly applied across feature maps, FPGA accelerators can efficiently implement:
- Parallel multiply-accumulate (MAC) units
- Streaming pipelines
- Reusable on-chip buffers
- Systolic array architectures
This significantly reduces external memory traffic, which is one of the main bottlenecks in neural network acceleration [7].
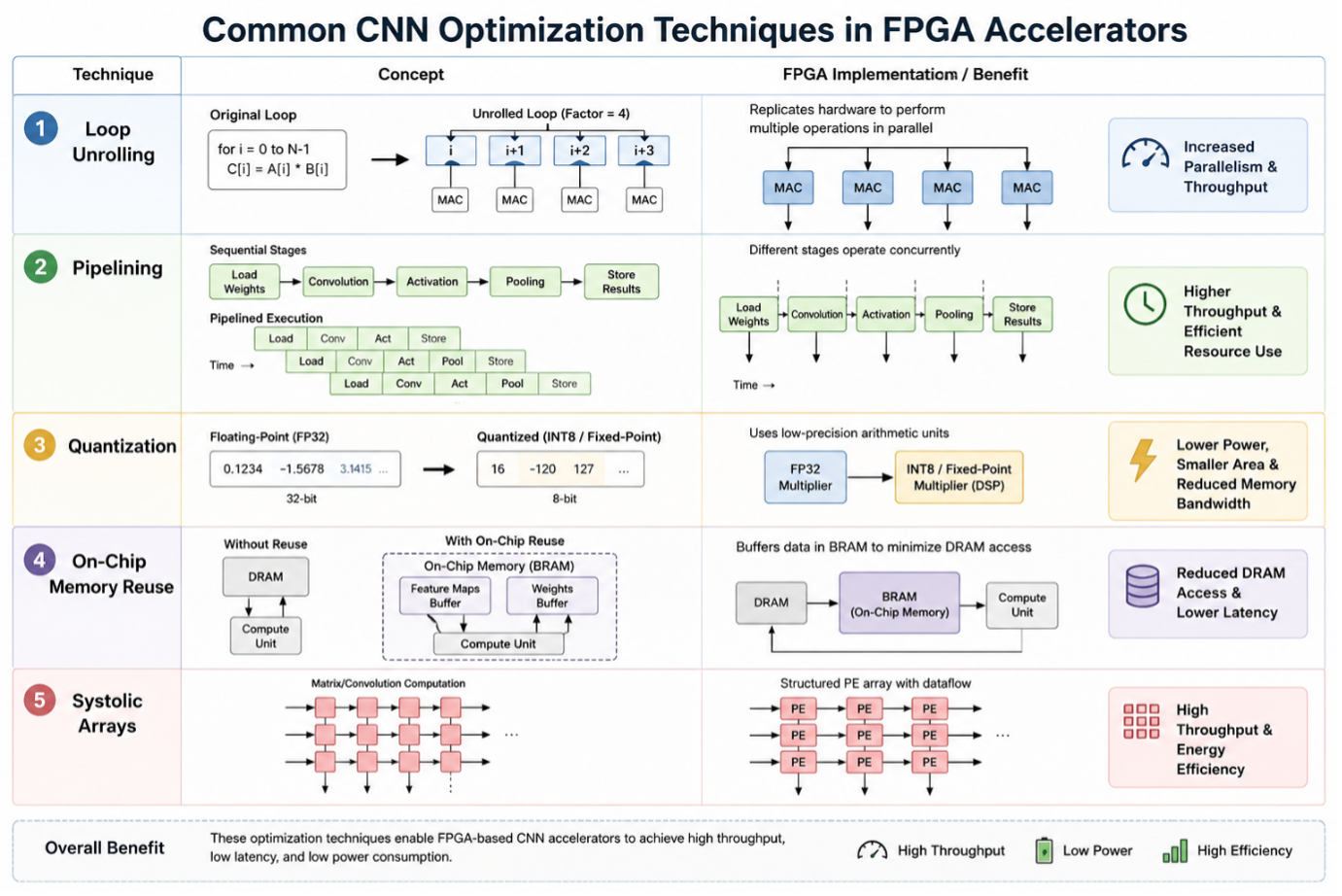
Common CNN Optimization Techniques
Several hardware optimization techniques are commonly employed in FPGA-based CNN accelerators to improve throughput, reduce latency, and enhance energy efficiency [8].
1. Loop Unrolling
Loop unrolling replicates loop iterations in hardware, enabling multiple operations to be executed concurrently. This technique increases parallelism and improves computational throughput by reducing sequential execution overhead.
2. Pipelining
Pipelining allows different stages of inference computation to operate simultaneously. By overlapping operations across multiple pipeline stages, FPGA accelerators can achieve high throughput and efficient hardware utilization.
3. Quantization
Quantization replaces floating-point arithmetic with lower-precision numerical formats such as INT8, fixed-point, or mixed-precision representations. This approach reduces hardware complexity, memory bandwidth requirements, and power consumption while maintaining acceptable inference accuracy.
4. On-Chip Memory Reuse
To minimize expensive off-chip memory accesses, intermediate feature maps and network weights are buffered within on-chip memory resources such as BRAM. Efficient data reuse significantly reduces memory access latency and external memory traffic.
5. Systolic Array Architectures
Systolic arrays consist of structured processing-element networks designed to efficiently accelerate matrix multiplication and convolution operations through localized data movement and high computational parallelism. Collectively, these optimization techniques enable FPGA-based CNN accelerators to achieve high throughput and low power consumption while maintaining scalable and efficient inference performance.
Transformer Architectures on FPGA
Why Transformers Are More Challenging
Transformers fundamentally differ from CNNs because they rely on self-attention mechanisms instead of convolution kernels. Unlike CNNs, Transformer inference requires:
- Large-scale matrix multiplications
- Global data dependencies
- High memory bandwidth
- Softmax and normalization operations
- Dynamic computation flows
These characteristics make efficient FPGA implementation significantly more difficult [9][10].
Major FPGA Challenges for Transformers
Despite the advantages of FPGA-based acceleration, implementing Transformer models on FPGA platforms introduces several architectural and computational challenges.
1. High Memory Bandwidth Requirements
Self-attention layers require frequent accesses to large intermediate matrices, including query, key, and value tensors. These data structures often exceed the capacity of on-chip memory resources, leading to increased external memory traffic and bandwidth pressure.
2. Quadratic Complexity
Attention complexity scales quadratically with sequence length: O(n²). This creates scalability issues for long sequences and large models.
3. Irregular Memory Access
Unlike CNNs, Transformers exhibit irregular access patterns that reduce memory locality and data reuse efficiency.
4. Nonlinear Operations
The softmax operation and scaling in self-attention are non-linear, making them expensive to implement in hardware compared to simple matrix multiplications, often requiring specialized FPGA resource allocation.
To address these challenges, recent FPGA research focuses on sparse attention mechanisms, runtime reconfiguration, custom matrix multiplication engines, and approximate computing techniques.
Edge AI Perspective
In edge computing systems, FPGA deployment decisions often involve balancing:
- Accuracy
- Latency
- Energy consumption
- Hardware resource utilization
CNNs continue to dominate real-time embedded applications because they can achieve deterministic low-latency inference with relatively small hardware footprints [7]. Transformers are increasingly used in advanced applications such as:
- Vision Transformers (ViT)
- Large Language Models (LLMs)
- Multimodal AI systems
However, deploying Transformer models on resource-constrained FPGA devices remains an active research challenge due to memory and bandwidth limitations [7].
Conclusion
FPGAs provide a highly promising platform for accelerating neural network inference thanks to their flexibility, energy efficiency, and customizable hardware architectures. CNNs are particularly well-suited for FPGA acceleration due to their highly structured convolution operations, which enable efficient data reuse, predictable memory access patterns, and high utilization of parallel MAC units. As a result, CNN accelerators can achieve high throughput with relatively low hardware complexity.
Transformers, however, are rapidly becoming dominant in modern AI systems due to their superior contextual learning capabilities. Although FPGA acceleration for Transformers introduces substantial challenges related to memory bandwidth and irregular computation patterns, recent research continues to improve the efficiency of Transformer-oriented FPGA architectures.
As edge AI systems continue to evolve, FPGA-based accelerators are expected to play an increasingly important role in enabling efficient deployment of both CNN and Transformer models. The comparison between these architectures represents not only a software challenge but also a critical hardware-software co-design problem for next-generation intelligent systems.
References
- [1] Mittal, S. (2020). A survey of FPGA-based accelerators for convolutional neural networks. Neural computing and applications , 32 (4), 1109-1139.
- [2] Ashish, V. (2017). Attention is all you need. Advances in neural information processing systems , 30 , I.
- [3] Ma, Y., Cao, Y., Vrudhula, S., & Seo, J. S. (2018). Automatic compilation of diverse CNNs onto high-performance FPGA accelerators. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 39(2), 424-437.
- [4] Wang, E., Davis, J. J., Zhao, R., Ng, H. C., Niu, X., Luk, W., ... & Constantinides, G. A. (2019). Deep neural network approximation for custom hardware: Where we've been, where we're going. ACM Computing Surveys (CSUR) , 52 (2), 1-39.
- [5] Ma, Y., Cao, Y., Vrudhula, S., & Seo, J. S. (2017, February). Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (pp. 45-54).
- [6] Zhang, C., Li, P., Sun, G., Guan, Y., Xiao, B., & Cong, J. (2015, February). Optimizing FPGA-based accelerator design for deep convolutional neural networks. In Proceedings of the 2015 ACM/SIGDA international symposium on field-programmable gate arrays (pp. 161-170).
- [7] Sze, V., Chen, Y. H., Yang, T. J., & Emer, J. S. (2017). Efficient processing of deep neural networks: A tutorial and survey. Proceedings of the IEEE , 105 (12), 2295-2329.
- [8] Gao, L., Luo, Z., & Wang, L. (2025). Convolutional neural network acceleration techniques based on FPGA platforms: Principles, methods, and challenges. Information , 16 (10), 914.
- [9] Rati, G., Costa, R., & Ishikawa, L. (2025). High-Performance FPGA Acceleration for Transformer-Based Models.
- [10] Tzanos, G., Kachris, C., & Soudris, D. (2022, December). Hardware acceleration of transformer networks using fpgas. In 2022 Panhellenic Conference on Electronics & Telecommunications (PACET) (pp. 1-5). IEEE.